About
The Usable Privacy Policy Project
Natural language privacy policies have become a de facto standard to address expectations of “notice and choice” on the Web. Yet, there is ample evidence that users generally do not read these policies and that those who occasionally do struggle to understand what they read. The Usable Privacy Policy Project builds on recent advances in machine learning, natural language processing, privacy preference modeling, crowdsourcing, formal methods, and privacy interfaces to overcome this situation.
You can learn more about the Usable Privacy Policy Project, including our approach, affiliated organizations, publications, and recent news, at www.usableprivacy.org.
Human-Annotated Privacy Policies
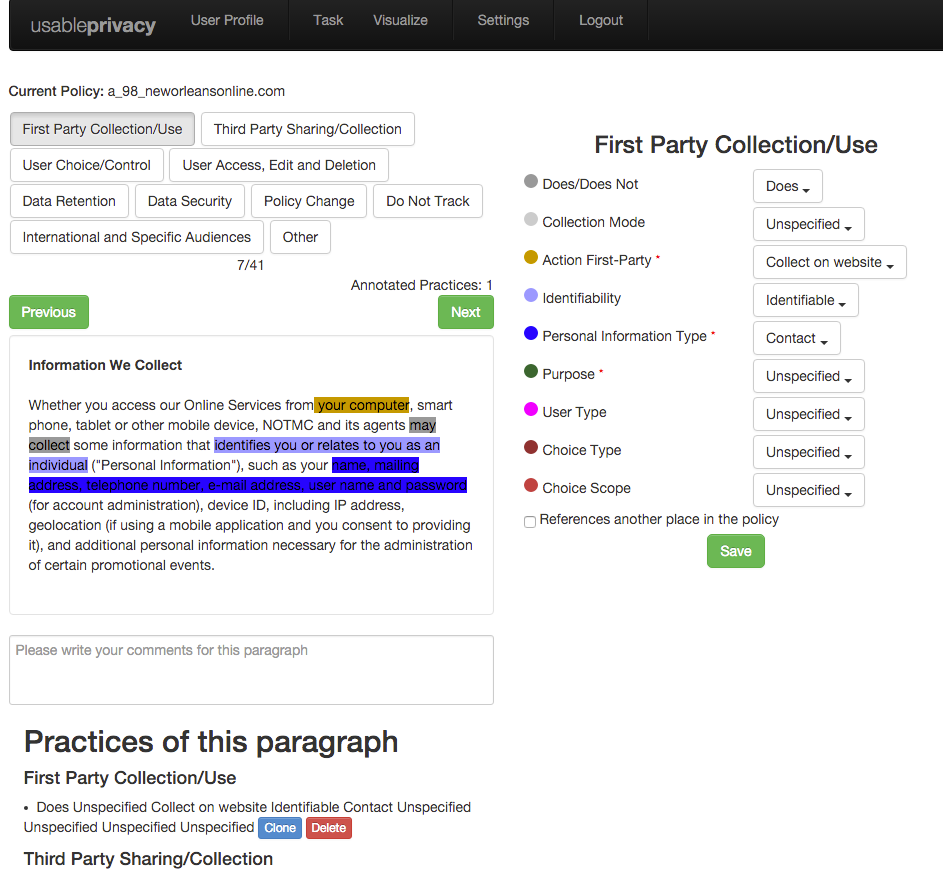 Annotation tool used to collect the OPP-115 Corpus
Annotation tool used to collect the OPP-115 CorpusYou can explore data and analysis results created by the Usable Privacy Policy Project. Search for specific websites to see their privacy policy overlaid with highlights for specific data practices. The shown data practice statements are the result of a large-scale annotation effort that involved ten law students. The students annotated the policies according to a fine-grained annotation scheme that we developed to comprehensively capture the content of privacy policies. Among others, the data practice statements cover the collection and use of information by the first party (that is, the website operator), sharing of information with third parties (such as ad networks), and user access and choice options. The rich policy corpus we gathered is intended to provide insights into the composition and content of privacy policies and how different policies compare with one another.
Contact Us
If you have questions concerning our project or if you are interested in collaborating with us, please contact the project’s lead principal investigator Prof. Norman Sadeh. Please subscribe to our public mailing list to receive news and updates about the project.
Sponsor

This project is a Frontier project funded by the National Science Foundation under its Secure and Trustworthy Computing initiative (CNS-1330596)